Apache Iceberg and changes above Hive
当我们说一个东西是屎山的时候,它最好真的不是…「大数据」这个词在很长一段时间事实标准就是 Apache Hadoop 下那堆东西,因为历史原因,很多东西实际上在 Hive / Spark 之类的东西上有一套实现和名词,这套名词本身可能比较草台班子:比如 Bucket / Partition 这些东西,在各个系统有不同的叫法,有的东西可能直接和别的系统对应…
你一定想问这些东西和 iceberg 有什么关系了,答案是息息相关。Iceberg 本身就是一帮人受不了 Hive 折磨搞出来的,在文档里三步一提 Hive,关系比亲爹还亲,然后 Iceberg 又只是一个 table format。这导致了几个后果:
- 在介绍 Iceberg 的时候,会不断介绍 Hive 之前的设计为什么导致了 Iceberg 会这么做…这导致其实你得对 Hive 有个基本的认知。妈的,我为啥要对这种老草台系统有认知…
- Iceberg 只是一个 Table format,它有的时候甚至会跑在 HMS 上。同时,Iceberg 很多时候只说明了「需要这么做」,实现行为还是要自己决定的,所以很多时候实现行为是各家一坨屎,e.g:
- Spark Partition: https://iceberg.apache.org/docs/latest/spark-writes/
- Hive Partition: https://iceberg.apache.org/docs/latest/hive/
我们这里会介绍一下 Hive 和 iceberg format,这个文档会持续更新,因为笔者可能认知也是会更新的。然后也会简单介绍一下 Snowflake、StarRocks 的行为是怎么兼容 iceberg 的。
所谓数据湖
众所周知,Hive 本身的设计中,存储 Partition 以目录的形式,而存储 Bucket 以目录下文件的形式存放。这样 Partition 裁剪,Bucket Join 之类的操作本身是很正常的,但是在 Hive 查询的时候,对超大表会有一些很奇怪的问题。比如 Meta 信息拿到分区之后 List 过慢、对 Underlying NameNode 的依赖等。很自然的,这套东西还可以移动到 S3 之类的存储上,但是 S3 之类的存储也有问题。
Apache Iceberg 名义上定位其实很低,它定位为对 OSS 之类的存储比较友好的 Table Format,它表层面的 RFC 变动相当克制,带来了一些格式兼容性。继承了一些 Hive 比较好的地方,比如哪个傻大个都可以往里写,同时在 Partition / Bucket / Schema 等方向上做出了演进或者限制,带来了比较细致的演进方式。
Iceberg 经常和「数据湖」这个词一起被提起,而不是我们之前说的 Table Format。这个词更多是个宣传用词,按我之前的理解( https://blog.mwish.me/2022/05/01/Delta-Lake-Lakehouse/ ),Data Lake 意味着:
- ACID 的能力,防止 Job 跑到一半挂了又没法处理
- 柔性的 Schema
- Streaming 等接口
- SQL 相关的 Pruning,Min-Max
- 对应的 Format Compaction / Auto-Clustering,包括 z-ordering
过了一年多,回顾这个结论,确实是我当时结论问题没那么大,但是这些是核心语义吗?其实回头来想,Apache Iceberg 不是一个很 Fancy 的东西,但却是一个很可怕的东西,新的数据湖产品,像 Snowflake,StarRocks, Doris 这些产品,都开始兼容了 Apache Iceberg 协议。然后 DeltaLake 感觉在路子上是更加靠前的产品,但是在 Apache Iceberg 的「攻势」下也开始部分开源了(笑)。
所以回过头来,也结合网易那几篇文章的理解:
- 从 Hive 这条路线的演进,看 Apache Iceberg 是一个 Table Format,它把表结构(表,Bucket,分区)抽离了物理的 Layout,从目录的部分依赖走到了自己拆分出一层逻辑的 Manifest 层。同时,也做了一些对原子 ACID 之类的支持(和部分反对者说的不完全一样,Hive 也支持 ACID,不过折腾的很别扭,而这在 Apache Iceberg 中师一等公民)
- Delta 也类似,拆分出一套日志层(甚至依赖 DynamoDB)来做提交
但是,从外部用户的视角来理解:
- 引擎平权,Apache Iceberg 是一套标准,用户可以尽量不 Lock-In 在某个系统中(而引擎当然巴不得你 Lock-In),包括猫猫狗狗都可以来根据这个 Format 去读 / 写对应的结构,写入的数据也可以是具体实现无关(Parquet,Avro,…)相当于自身的结构是开放的。
- 写入数据和 Schema 很方便,包括很多情况下,导入数据 - 加列 之后,数据符合某种标准。同时,数据只要符合某种 Schema 即可(Apache Iceberg 允许 Avro,Parquet,Orc 等多种数据)
- ACID,这里并不同于 TP 数据库的快速小事务,这里更多是要求 abortable / 隔离性 这样的需求。我在之前其实是列了 Streaming 需求的,但是其实这个就类似 AP 测向 TP 测靠拢,属于大家却是不清楚这个做了是不是真的有收益的环节了。
- CDC?其实我并不知道是不是用户真的需要 CDC 之类的需求,但是某种意义上(去掉 Compaction)很多场景做 CDC 确实是非常自然的场景了。
(Optimize 和 Compaction 感觉很必要,但是暂时不在列)
这个时候你就会发现,有的东西确实是 Hive 有的,但是它指向了一个更混沌开放的领域。和我之前理解不完全一样的是,这里确实要有一些 Schema 限制,但并不是整体 Enforce 某个 Schema,而是一些读时模式 + 列变换的限制。
今天就简单介绍一下 Apache Iceberg 的 Spec
Hive 的缺陷
Hive 可能现在不怎么用了,但是 Hive 的表结构还是数据的事实标准。在这个世界还青春的时候,Spark 的 Core 本身作为一套计算的逻辑维护 RDD。之后感觉很多引擎推进的都是计算上的方式,而存储的方式很多还是在 Hive 上或者自己去搞 Share nothing。Hive 在很长一段时间至少在表结构上还是 de-facto 的主导者。Hive Table Format 如下:
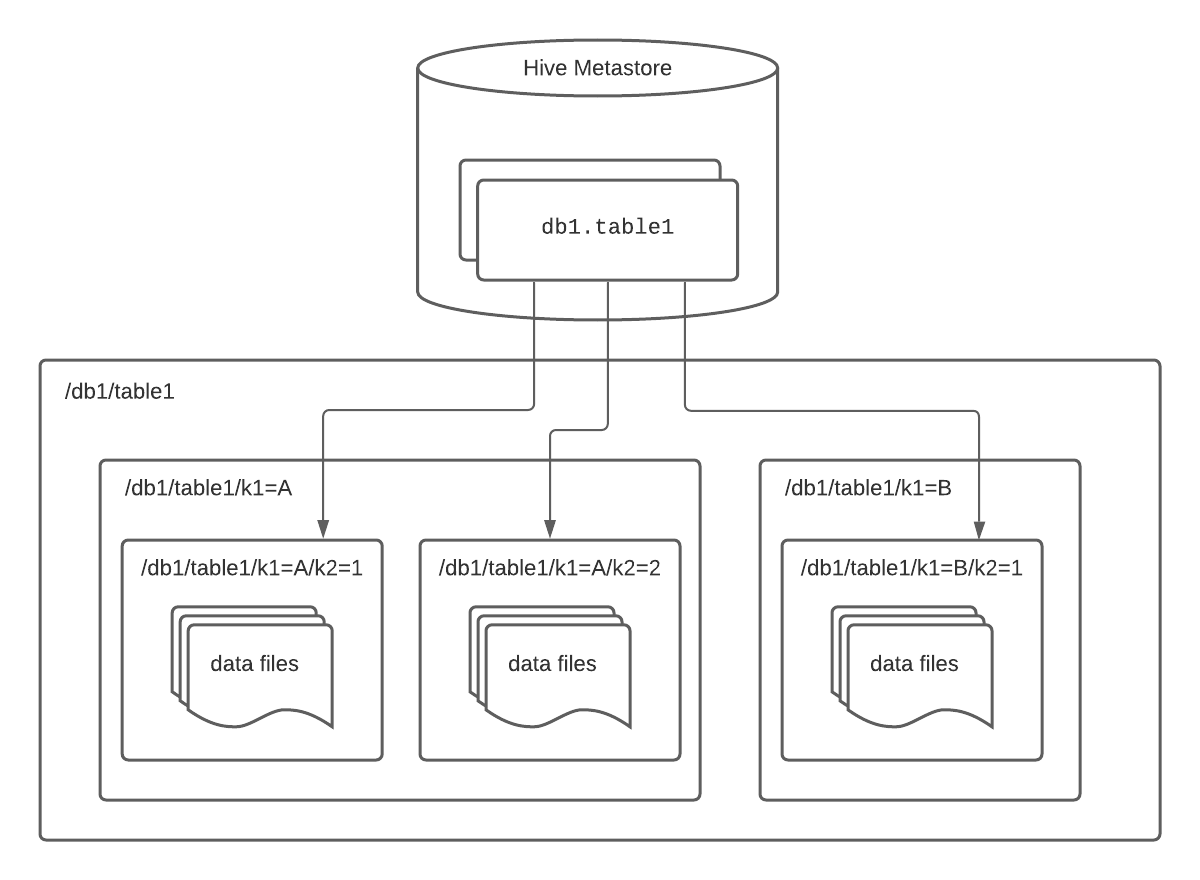
然而,这里列出来一些缺点:
- Hive ACID 通过 fs rename 来实现。在 POSIX 上,rename 可以是原子的。然而 S3: ?
- 没有 WAL 之类的方式,无法原子性写多个 Partition
- 无法对多个写同一个 Partition 的 Txn 作出什么限制
- 需要依赖
List,可能会开销很长的时间 (分区多或者分区的文件多都会加重这个问题,而且 S3 的 List 本身就很昂贵,见 https://www.youtube.com/watch?t=138&v=nWwQMlrjhy0&feature=youtu.be ) - 用户需要手动写分区,因为在 Hive 中,分区列并不是表数据的一部分,要手动写对应的分区信息
- Hive 的 Table Statistics 常常并不准确(显然数据库都不那么准确?)
- 在 OSS 中,Hive 的路径
/path/to/table/partition_column=partition_value限制了物理路径的打散能力,导致可能落在几个固定的节点上,造成一定的性能问题。(本质上还是对物理路径的依赖?)
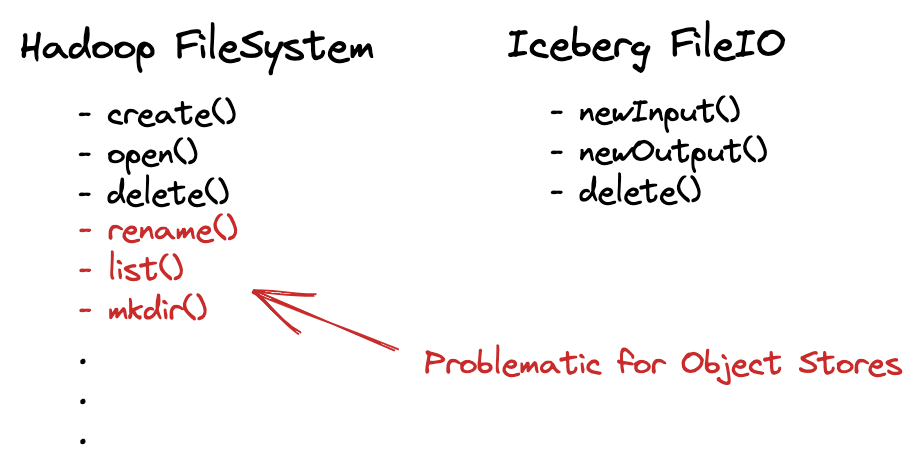
Iceberg
Netflix 搞了一套新的 Table Format: Iceberg,主导者 Ryan Blue 随后也创建了公司。
Netflix 的思路是,发现 Table format 和 fs 目录的物理结构是完全绑定的,它们的简单设计是:
- 抽离这个物理 Directory 的层次,造了一个逻辑的 Directory
- Track 文件和文件的变更
- 用这套 Track 机制做了一套文件层面的 MVCC
- 把 Partition 机制融合进数据中

Iceberg 抽象了一套多层的架构:
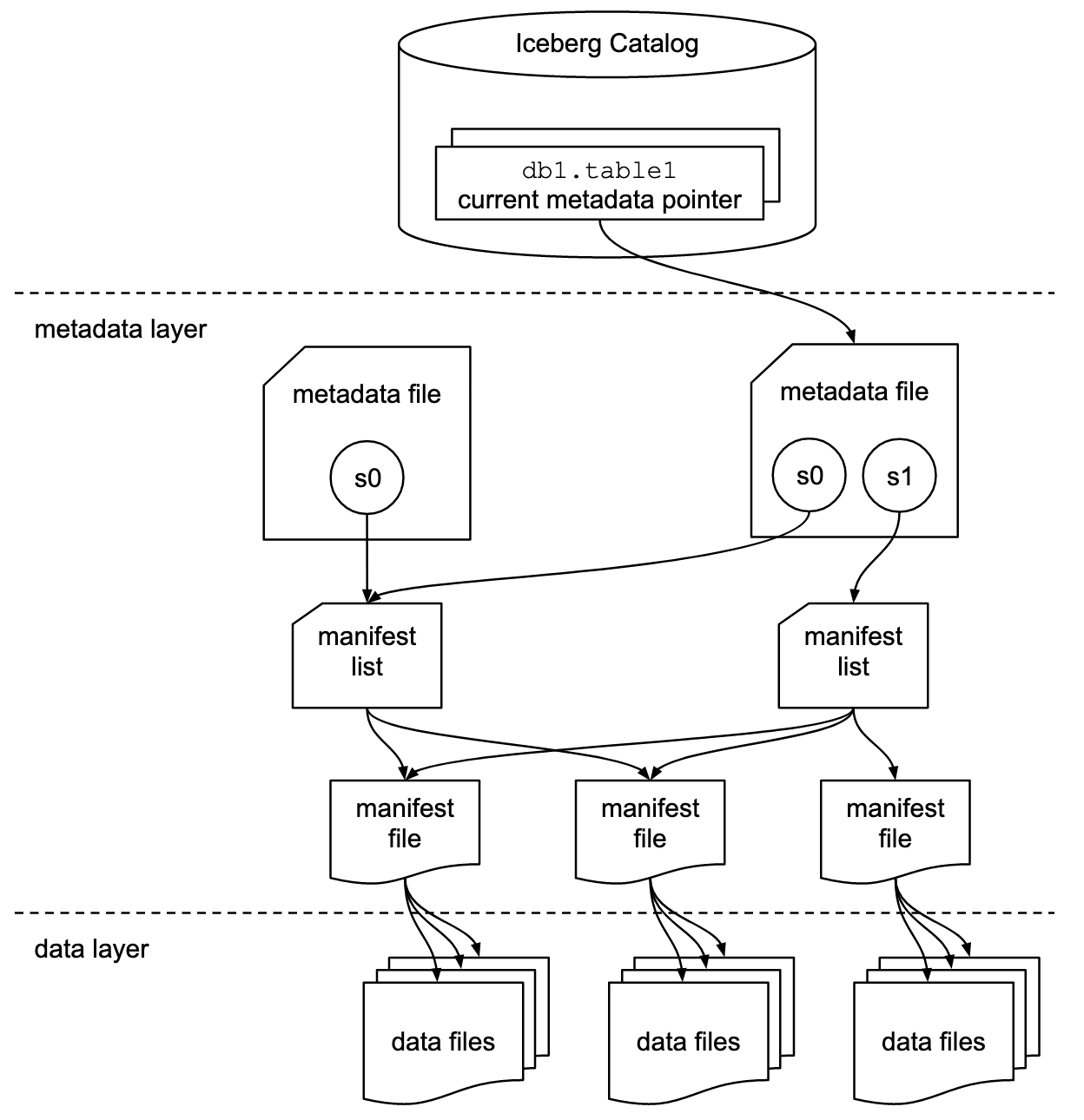
显然,中间层是 iceberg 的核心,但我们最后介绍:
- Data layer: 用户写 data 就写 data,没有挂在 list 上 commit,就不是表的一部分
- Iceberg Catalog: iceberg 整个结构的 root 指针,它可以是 HDFS / HMS 等,需要支持原子的变更
那下面比较重要的就是中间的结构了。
Iceberg Catalog Layer
Iceberg 的核心成员是「Table」,即数据库的一张表。截至目前(2025.10.1),Iceberg 本身也不支持多表的事务。这里 Catalog 本身提供两种能力:
- 它维护一个从 逻辑表名(例如
prod_db.user_events)到 当前有效的元数据文件物理路径(例如s3://bucket/warehouse/prod_db/user_events/metadata/00001-xxxx.metadata.json)的映射关系。 - 实际上,Catalog 本身在事务提交的时候,会需要做一层简单的 CAS 校验
在这里,https://database-doctor.com/posts/iceberg-is-wrong-1.html 说了一些比较精炼的总结。吐槽了一下这种判断 commit 是否合理的两种方式。
Iceberg Metadata Layer
首先还是需要注意,在数据库领域,我们经常提到 record, wal, page 之类的概念,而在大数据领域,某种意义上,数据的一等公民是文件。
Table Metadata and Snapshot
Table Metadata / Metadata File: 是一个 JSON,表达表的信息,包含表的 schema,Partition specs,格式的版本. ( The table metadata file tracks the table schema, partitioning config, custom properties, and snapshots of the table contents. A snapshot represents the state of a table at some time and is used to access the complete set of data files in the table. )
- Snapshot 可以视作一次写产生的 snapshot,snapshot 被内包含在 Metadata File 中。系统一定有一个当前的 Snapshot (对于刚创建的表,这个 snapshot 里面一个文件都没有)。Snapshot 也可以包含创建者的 Summary
举个博客中的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128{
// 在 iceberg 中的版本是 v1
"format-version" : 1,
// 对应的 table 生成的 uuid
"table-uuid" : "4b96b6e8-9838-48df-a111-ec1ff6422816",
// Table 的位置. 你可能要问了, 这个鬼玩意和 Hive 那样目录有啥区别,
// 答案是数据不在目录下也可以,但是三方引擎可能会按照这个来管理,是 “实践中的强制项,但理论上的建议项”。
"location" : "/home/hadoop/warehouse/db2/part_table2",
// table 最后更新的 unix epoch
// (其实这里还应该有一个最新的 sequence-id)
"last-updated-ms" : 1611694436618,
// 已经分配的最高的 column-id
"last-column-id" : 3,
// table 的 schema, 注意这里 id 的分配
// 这个东西已经 deprecated 了, 新一点的是 schemas,
// 就是包括历史有的 schema.
"schema" : {
"type" : "struct",
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : true,
"type" : "int"
}, {
"id" : 2,
"name" : "ts",
"required" : false,
"type" : "timestamptz"
}, {
"id" : 3,
"name" : "message",
"required" : false,
"type" : "string"
} ]
},
// Partition 相关的信息.
// 你可能注意到了 spec 和 specs
// spec 也已经 deprecated 了, 令人唏嘘
"partition-spec" : [ {
"name" : "ts_hour",
"transform" : "hour",
"source-id" : 2,
"field-id" : 1000
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "ts_hour",
"transform" : "hour",
"source-id" : 2,
"field-id" : 1000
} ]
} ],
// 排序的 key
// 其实 Sort 也比这个定义复杂, 还包括对应的
// SortOrder, null first 之类的.
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
// table 的属性, 可以用来控制 table 的读写
"properties" : {
"owner" : "hadoop"
},
// 指向 latest 的 snapshot id.
"current-snapshot-id" : 1257424822184505371,
"snapshots" : [ {
// snapshot
"snapshot-id" : 8271497753230544300,
"timestamp-ms" : 1611694406483,
// 关于写入的一些信息
"summary" : {
"operation" : "append",
"spark.app.id" : "application_1611687743277_0002",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "960",
"changed-partition-count" : "1",
"total-records" : "1",
"total-data-files" : "1",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
// 一个 snapshot 会有一个对应的 manifest list
"manifest-list" : "/home/hadoop/warehouse/db2/part_table2/metadata/snap-8271497753230544300-1-d8a778f9-ad19-4e9c-88ff-28f49ec939fa.avro"
},
{
"snapshot-id" : 1257424822184505371,
// 有的 snapshot 会有对应的 parent snapshot.
"parent-snapshot-id" : 8271497753230544300,
"timestamp-ms" : 1611694436618,
"summary" : {
"operation" : "append",
"spark.app.id" : "application_1611687743277_0002",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "973",
"changed-partition-count" : "1",
"total-records" : "2",
"total-data-files" : "2",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "/home/hadoop/warehouse/db2/part_table2/metadata/snap-1257424822184505371-1-eab8490b-8d16-4eb1-ba9e-0dede788ff08.avro"
} ],
// snapshot 时间对应上物理时间
"snapshot-log" : [ {
"timestamp-ms" : 1611694406483,
"snapshot-id" : 8271497753230544300
},
{
"timestamp-ms" : 1611694436618,
"snapshot-id" : 1257424822184505371
} ],
// 可选的 metadata 列表
"metadata-log" : [ {
"timestamp-ms" : 1611694097253,
"metadata-file" : "/home/hadoop/warehouse/db2/part_table2/metadata/v1.metadata.json"
},
{
"timestamp-ms" : 1611694406483,
"metadata-file" : "/home/hadoop/warehouse/db2/part_table2/metadata/v2.metadata.json"
} ]
}(说是版本 1,其实版本2 包含了一些 delete 之类的信息)
(其实我很好奇这个时间,如果遇到了分布式时钟回退怎么办)
这里表级别包含了文件的 Partition,Schema,Snapshots,和 snapshot 的 History。这里还有一些物理时间变更的信息。没有写清楚的是,这里还可以存储 table statistics 和 snapshot refs。table statistics 定义见:https://iceberg.apache.org/spec/#table-statistics 。Table Statistics 也以专门的 Puffin File 的形式存储。
注意,这里包含了: (可以看 https://github.com/apache/iceberg-rust/blob/dc349284a4204c1a56af47fb3177ace6f9e899a0/crates/iceberg/src/spec/table_metadata.rs#L143 , 这是 Version == 2 的 Table 元数据)
- Table 本身的 uuid、location
- Partition 如果有的话,是「存在的文件或者可能存在的文件的所有的 Partitions」,和一个 current partition id。
default-spec-id: 默认的 Partition Spec Id ( Rust 实现中使用Arc的形式,选择指向确认的对象)last_partition_id: 记录最高的 Partition Id- 如果 unpartition,也要写一个 unpartitioned spec,留空即可
- Schemas: 系统所有的 Schema(可能要求相互之间会有一定的兼容性,符合 Schema Evolution 的标准)
current_schema_id保留了现在的 schema idlast_column_id表示分配出去的 column-id 的最大值,用来给下一次 field id 作为 assign 的 id
- Sort Order 同 Partition
- Snapshots 保留了所有的 snapshots,然后有一个 current snapshot id。
last_sequence_number: iceberg 的 sequence number,在提交的时候验证用
Snapshot 则是 Iceberg TableMetadata 的一部分。这里 Snapshot 内容都会被呈现出来:
- Q: 为什么保留所有的 Snapshot 呢?
- A: 感觉这里原因大概是这样(我没有具体到社区问,但是自己可以想象一下):这里如果 snapshot 存成文件,plan 的时候,需要索引
sequence_number之类的东西帮助 plan,而 gc 的时候,则会更蛮烦,因为不知道文件会不会被引用。但是 snapshot 放在文件里面也要求这些东西大小相对比较小。这样可以直接在这一层做掉可见性观察和一些简单的可以回收的文件判断等(比如没有并发事务了,就可以 gc 掉早一些的东西了?)。总之还是 snapshot 拆分出了 Metadata File ( Manifest List ),让这里不会特别大。
我们再来看 Snapshot:
- Snapshot 有
snapshot_id, optional 的parent_snapshot_id. sequence_number,用于定序的 seq number- 这个 Summary 也比较有意思,能代表 snapshot 的来源,举个好玩的例子,Compaction 可以用
replace来表示。 - 可选的
schema_id。这个 schema 总感觉做到文件层也行,这里也可以带到文件层,我是觉得这个其实无所吊谓倒是。
Metadata File (Manifest List)
Manifest List 对应一个 Snapshot,以一个 Avro 文件的形式存在。Snapshot 本身 inline 在了 Metadata 里面,但是 Manifest List 却被抽出来了。这种抽象也算是避免进一步膨胀。同时,Manifest List 是一个完成的 snapshot,它包含了一些 Manifest。而这些 Manifest 比较值得玩味:
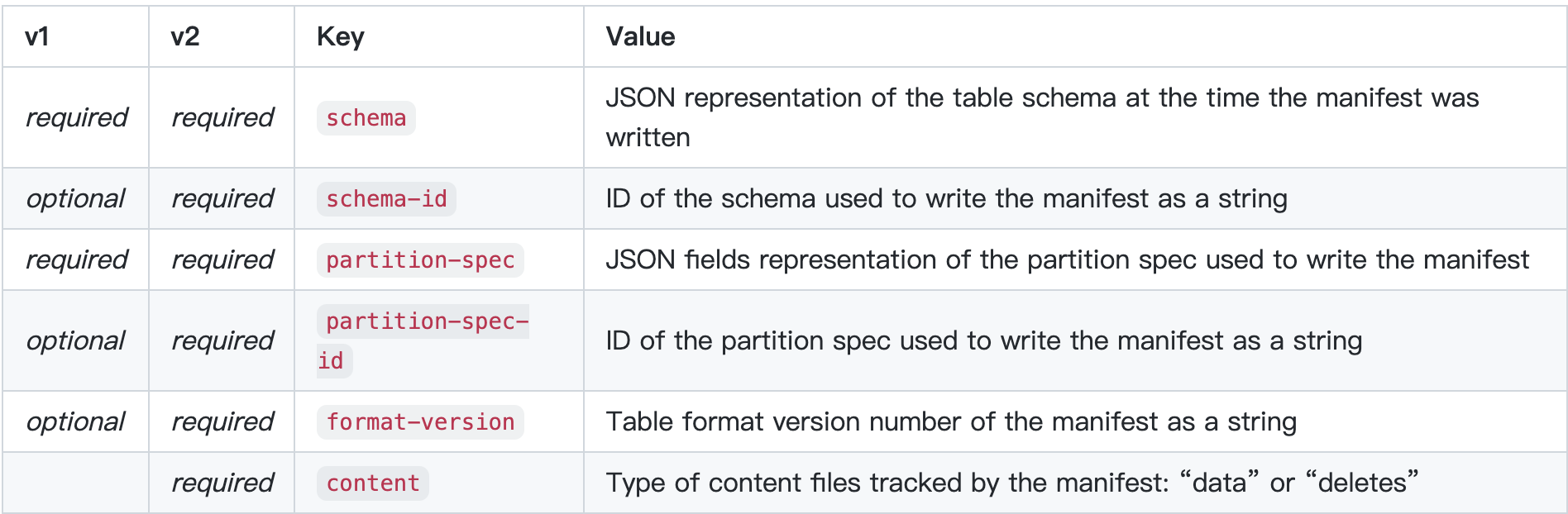
- Manifest 本身按照 Table 或者 Partition 有切分,这里需要写 Manifest File 的
partition_spec_id,查询可以跳过一定的 Manifest,这里也明示了不同 Partition 的文件要计入不同的 Manifest file - 这里 Manifest 也可以被当成 Log,快速写插入一个文件,然后加入 Manifest List,这项技术被称为 fast append。Manifest FIle 有
content,标注自己类型是 Added 还是 Deleted。这里实际上只是记录操作的类型,一个 Manifest 里面可以同时有 Added 和 Deleted,这只是告诉你事件上是 add 还是 delete。 - 大表也可以拆分 Manifest,来某种意义上加速 Planning(本质上是看怎么裁剪,怎么流式处理文件列表,和这些具体大不大,还是一个很看实现的东西)
- 这里还有一些「增加了多少行/删了多少行/存在多少行」之类的统计信息
上面可以看 https://iceberg.apache.org/docs/latest/configuration/ 配置中一些有关的,比如:
commit.manifest.target-size-bytescommit.manifest.min-count-to-merge
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81{
// 需要注意的是, 在 v2 上, 这里还有个 sequence number
// manifest 对应的路径.
"manifest_path": "/home/hadoop/warehouse/db2/part_table2/metadata/eab8490b-8d16-4eb1-ba9e-0dede788ff08-m0.avro",
"manifest_length": 4884,
"partition_spec_id": 0,
"added_snapshot_id": {
"long": 1257424822184505300
},
// 这些字段算是 table summaries, 表达对应的增 / 删
"added_data_files_count": {
"int": 1
},
"existing_data_files_count": {
"int": 0
},
"deleted_data_files_count": {
"int": 0
},
// 包含的 Partition 相关的信息
// 这里还可以记录 Partition 相关的和 field-summary,
// 做进一步的分区裁剪.
"partitions": {
"array": [ {
"contains_null": false,
"lower_bound": {
"bytes": "¹Ô\\u0006\\u0000"
},
"upper_bound": {
"bytes": "¹Ô\\u0006\\u0000"
}
} ]
},
"added_rows_count": {
"long": 1
},
"existing_rows_count": {
"long": 0
},
"deleted_rows_count": {
"long": 0
}
}
{
"manifest_path": "/home/hadoop/warehouse/db2/part_table2/metadata/d8a778f9-ad19-4e9c-88ff-28f49ec939fa-m0.avro",
"manifest_length": 4884,
"partition_spec_id": 0,
"added_snapshot_id": {
"long": 8271497753230544000
},
"added_data_files_count": {
"int": 1
},
"existing_data_files_count": {
"int": 0
},
"deleted_data_files_count": {
"int": 0
},
"partitions": {
"array": [ {
"contains_null": false,
"lower_bound": {
"bytes": "¸Ô\\u0006\\u0000"
},
"upper_bound": {
"bytes": "¸Ô\\u0006\\u0000"
}
} ]
},
"added_rows_count": {
"long": 1
},
"existing_rows_count": {
"long": 0
},
"deleted_rows_count": {
"long": 0
}
}Iceberg 也有一个提案来减少对应的文件数量,见:https://docs.google.com/document/d/1k4x8utgh41Sn1tr98eynDKCWq035SV_f75rtNHcerVw/edit?tab=t.0#heading=h.unn922df0zzw
Manifests
在 v2 中,format 还允许标注 Manifest 为 Delete Manifest. 这个 Manifest 就是单纯一个 「文件列表」了,我们真的走了好一会儿才看到这里呢…
Manifest 本身有点像 G+ 写的那篇 when metadata is bigdata. 整个会记录一致的 Schema 和 data_file 层面的统计信息,来进行分析,我们接着看一个 v1 的文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98{
// (existing / add / deleted )
"status": 1,
// 插入的 snapshot id
"snapshot_id": {
"long": 1257424822184505300
},
// (这里还隐含了 seq-number 和 file-seqnumber, 因为这个文件
// 本身是一个 v1 文件, 所以不包含, 当读取的时候, 这里有一套继承机制)
"data_file": {
"file_path": "/home/hadoop/warehouse/db2/part_table2/data/ts_hour=2021-01-26-01/00000-6-7c6cf3c0-8090-4f15-a4cc-3a3a562eed7b-00001.parquet",
"file_format": "PARQUET",
"partition": {
"ts_hour": {
"int": 447673
}
},
"record_count": 1,
"file_size_in_bytes": 973,
"block_size_in_bytes": 67108864,
"column_sizes": {
"array": [ {
"key": 1,
"value": 47
},
{
"key": 2,
"value": 57
},
{
"key": 3,
"value": 60
} ]
},
"value_counts": {
"array": [ {
"key": 1,
"value": 1
},
{
"key": 2,
"value": 1
},
{
"key": 3,
"value": 1
} ]
},
"null_value_counts": {
"array": [ {
"key": 1,
"value": 0
},
{
"key": 2,
"value": 0
},
{
"key": 3,
"value": 0
} ]
},
"lower_bounds": {
"array": [ {
"key": 1,
"value": "\\u0002\\u0000\\u0000\\u0000"
},
{
"key": 2,
"value": "\\u0000„ ,ù\\u0005\\u0000"
},
{
"key": 3,
"value": "test message 2"
} ]
},
"upper_bounds": {
"array": [ {
"key": 1,
"value": "\\u0002\\u0000\\u0000\\u0000"
},
{
"key": 2,
"value": "\\u0000„ ,ù\\u0005\\u0000"
},
{
"key": 3,
"value": "test message 2"
} ]
},
"key_metadata": null,
"split_offsets": {
"array": [
4
]
}
}
}这里就可以咔咔杀文件了. 回顾一下,这里每一个层次都有统计,Manifest
即是神又是魔(这是我中二犯了)既能删除又能添加,同时提供了 Prune 文件的能力。这里提供了- Metadata: Schema-id, partition-id, content-type
File Format
其实 File Format 层面,Iceberg 类似 Arrow Parquet 那套。什么意思呢?它不能适应任何格式,但是会需要你这个格式预留一些符合它 spec 的东西,比如:
- FieldId:https://github.com/apache/iceberg/blob/master/format/spec.md#column-projection
- Default Value (and spec):iceberg/spec.md at master · apache/iceberg
- 这里提供了
initial-default(添加字段的时候的默认值)和write-default(写入的默认值)
- 这里提供了
- 类型:https://github.com/apache/iceberg/blob/master/format/spec.md#schemas-and-data-types 这里限制的还是相对比较死的
Row-Level Delete Formats
Iceberg format v2.0 提供了 Delete format. 这里有 Positional-Delete File 和 Equality Delete-File
- Positional Delete File: 对文件提供删除,以行的形式标记删除
- Equality Delete-File: 对文件提供删除,以某个 Column 的 Value 形式全部删除
这里文件也要提供对应的 Stats,比如删除文件也要提供自己删除的 Stats。
Iceberg 的 Stats 比较有意思,语义是:「你可以不提供,但是只要你提供了,就必须是全都准确的」。
这里还要注意,一个 Delete File 可以对应多个 Base 文件,Equality Delete-File 甚至可以对应多个分区。
Concurrency Control and Sequence Number
Apache Iceberg 没有 row-level transaction 和 row-level mvcc,取而代之,它模型关键是 Snapshot / 文件级别的 MVCC:
- 每个 snapshot 有一个 sequence number
- 尝试提交的时候,Apache Iceberg 以 OCC 的协议提交,在前面申请一个 Sequence number,然后在 validation 阶段做 checking
- 创建的新 Delete / Insert 继承新的 Snapshot 的 Sequence Number,而之前创建的(Existing)享有之前的 Sequence number
- 因为这套机制,Compaction 前后文件其实是不太一致的,令人唏嘘。
Partition / Bucket / Sorting
Partition Evolution & Sort Order Evolution
Iceberg 通过 PartitionSpecs 和 Sort Order 的 Specs 的方式来提供相关的内容。Hive Partition 不是数据表的一列,但是 Iceberg Partition 可以选择
expr-transform(表的一列),比如它 spec 要求是- A source column id from the table’s schema
- A partition field id that is used to identify a partition field and is unique within a partition spec. In v2 table metadata, it is unique across all partition specs.
- A transform that is applied to the source column to produce a partition value
- A partition name
这里举个之前的例子:
1
2
3
4
5
6
7
8
9
10"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "ts_hour",
"transform" : "hour",
"source-id" : 2,
"field-id" : 1000
} ]
} ],这个地方就很直观介绍了 Partition 的模样。在 Manifest 上也有 partition-spec:
类似 Partition,Bucket 也做成 Partition 的内容,可以套:
1
2
3
4
5
6
7
8
9
10
11[ {
"source-id": 4,
"field-id": 1000,
"name": "ts_day",
"transform": "day"
}, {
"source-id": 1,
"field-id": 1001,
"name": "id_bucket",
"transform": "bucket[16]"
} ]其实 Sort Order 也差不多就是这套 Rule,下面来介绍
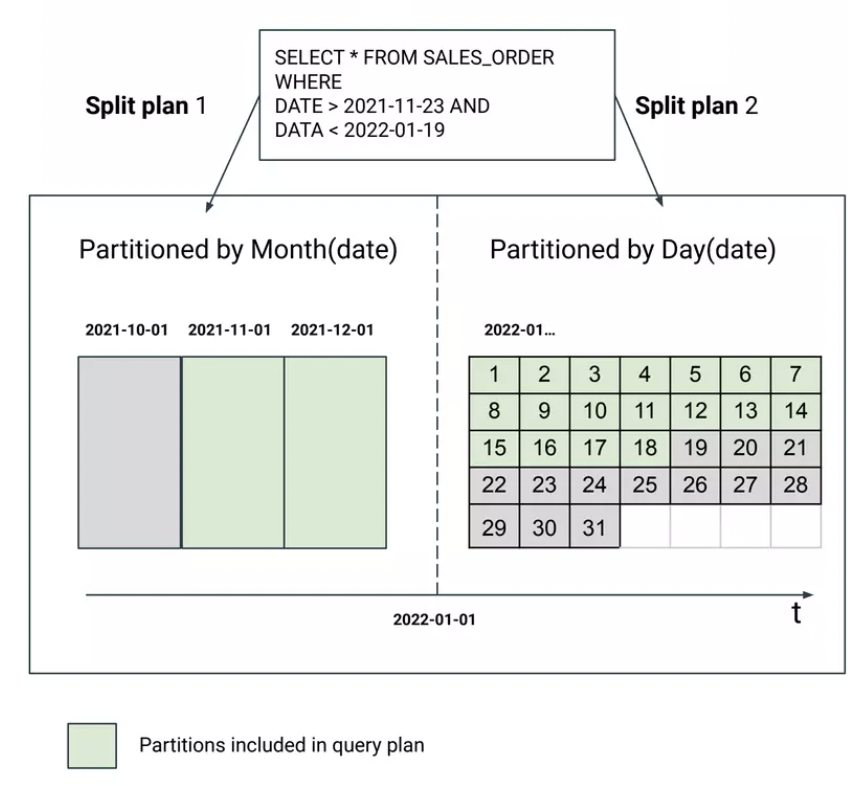
Wrapup: How does Iceberg run query
比较细节的部分在 Spec 的 Scan Planning 部分:https://iceberg.apache.org/spec/#scan-planning
- 找到 Iceberg Catalog,拿到 Metadata file
- DELETED 的文件不会参与 Planning,专注处理 EXISTING 和 ADDED
- 裁剪分区
下面有一些 DELETED File Apply 的规则:
- 对于 Position,这里会根据 ts-rule 来 apply,如果是分区表,必须在同一个分区做删除
- 对于 Equality,这里会根据 ts-rule 来删除,它可以是 unpartition 的,作用于全局
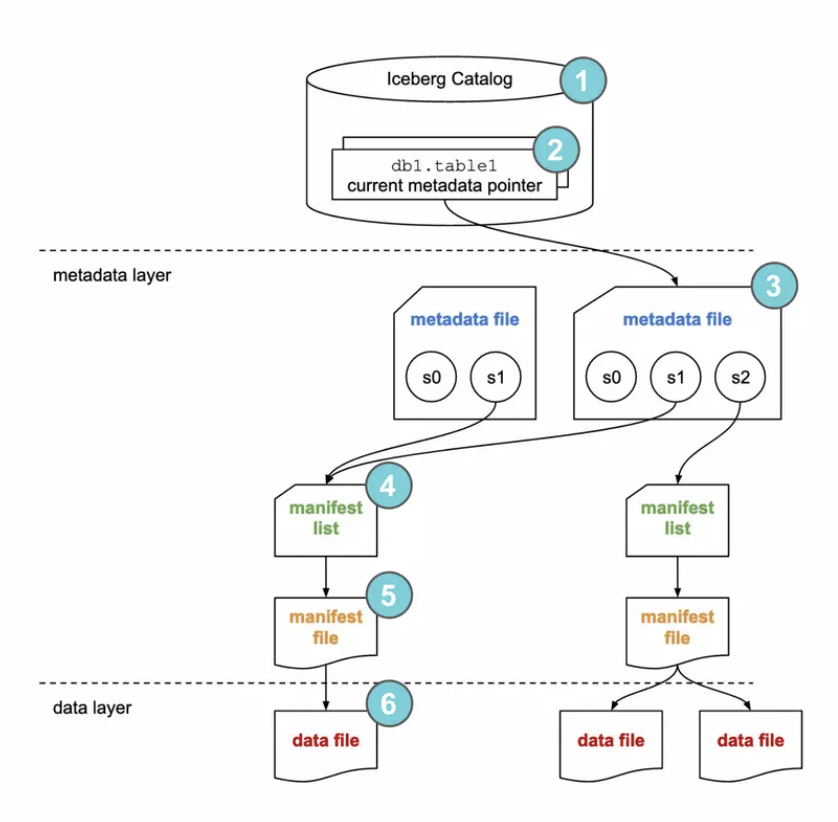
这样就可以 Plan 出对应的表,然后进行查询了。
Wrapup: How does Iceberg Commit
Iceberg 系统中,有一个
i64的sequence_number。这里有基于这个的提交,可以看下面的管理https://jack-vanlightly.com/analyses/2024/8/5/apache-icebergs-consistency-model-part-2
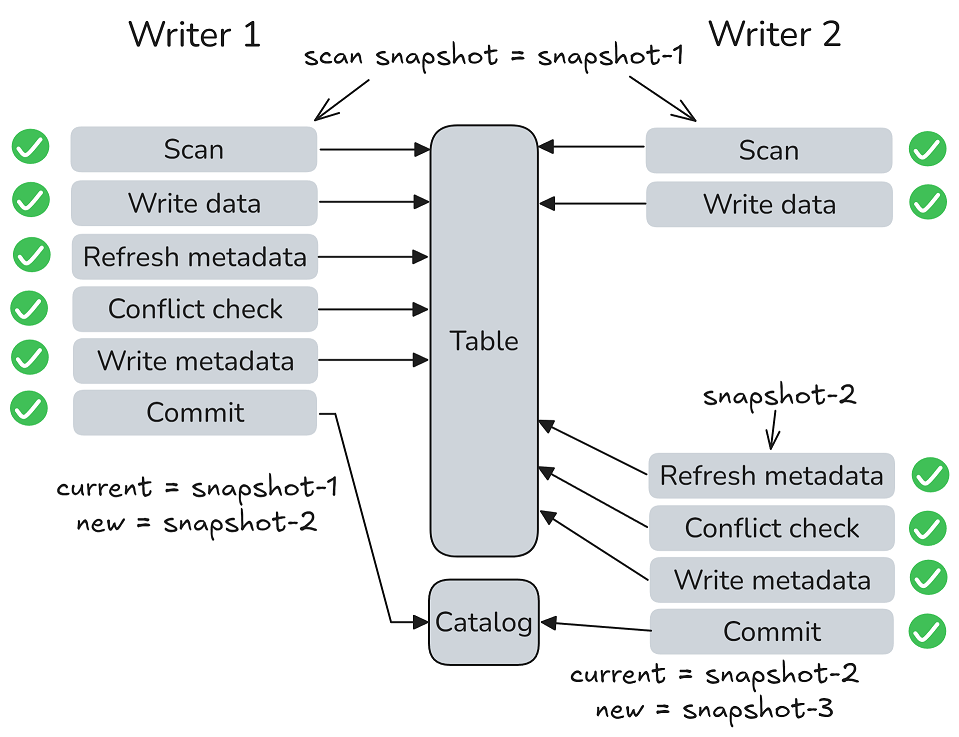
本质上,这是一种笨方法。我们可以想到,下面的场景也会需要 commit:
- 回收不可见的 snapshot,这里需要 commit 一次,来提交
- 删掉一个文件,这里可能要重新整理 ManifestList 甚至 Manifest
本质上,这里也是在说,snapshot 的回收不是系统内部的,而是一个外部概念。但本质上,这里还是一个很标准的 OCC 提交的流程,只是这里的槽点在于用一个 prev-id 来做提交的判断,这里对并发层做出了一定的限制。(当然,如果假设写事务数不会很多,那也没啥问题)。
DeltaLake 与其类似,本质上也是靠日志的提交冲突来判断(有点像 ByteGraph 2.0 的实现)。
Iceberg 兼容
Snowflake, StarRocks 这些系统都兼容了 Iceberg,我们以 Snowflake 为例,讲讲这块是怎么兼容的:
https://www.snowflake.com/blog/expanding-the-data-cloud-with-apache-iceberg/
- 从内部格式为生成 Parquet,可能会双写
- Manifest 层面去双写
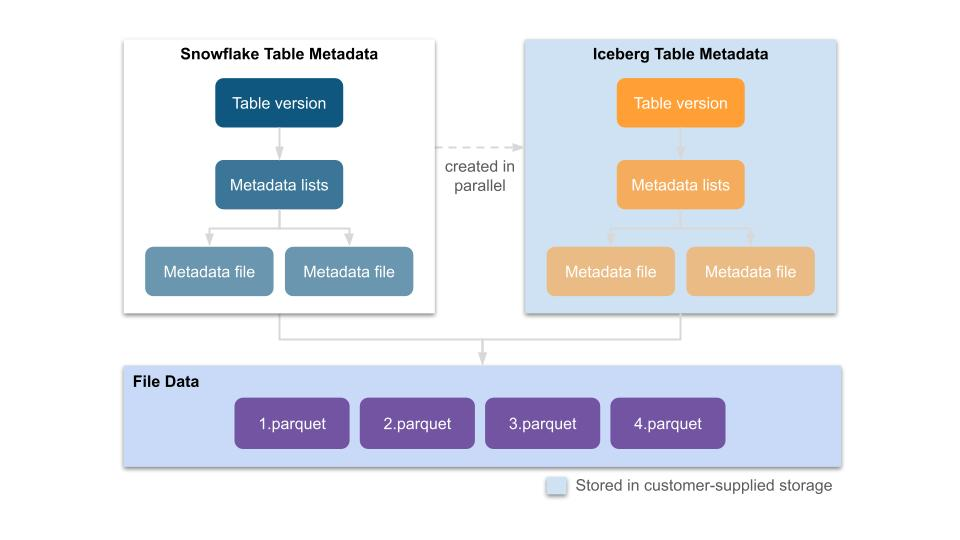
References
- [强烈推荐] https://www.dremio.com/resources/guide/apache-iceberg-an-architectural-look-under-the-covers/
- https://tabular.io/blog/iceberg-fileio/
- Iceberg V2 Spec: https://docs.google.com/document/d/1ZqVaSI_vBXekqXxNEg8NYvuiKgV2fKpMARhU54FhQaM/edit#
- Snowflake and iceberg
- Apache Iceberg 的设计哲学 - lfyzjck的文章 - 知乎 https://zhuanlan.zhihu.com/p/601654830
- 从 Delta 2.0 开始聊聊我们需要怎样的数据湖 - 网易数帆的文章 - 知乎 https://zhuanlan.zhihu.com/p/552390193
- 深度对比delta、iceberg和hudi三大开源数据湖方案 - openinx的文章 - 知乎 https://zhuanlan.zhihu.com/p/110748218
- 数据湖(Data Lake) 总结 - 我吃印度飞饼的文章 - 知乎 https://zhuanlan.zhihu.com/p/91165577