io_uring for High-Performance DBMSs: When and How to Use It
在Linux平台上,很长一段时间内,libaio 都是数据库里面访问异步 io 的唯一选择。Linus 曾经说过下面的比较负面的印象 [1],主要观点大概是:
- 并非真正的异步:在很多情况下(例如元数据操作、缓存 I/O),AIO 仍然会阻塞(block),违背了异步的初衷。
- 局限性太大:它几乎只能在开启
O_DIRECT(绕过页缓存)的情况下正常工作。这意味着如果你想利用操作系统的文件缓存(Buffered I/O),libaio基本上是废的。 - 受数据库厂商裹挟:Linus 认为这个功能主要是为了满足 Oracle 等数据库厂商的特定需求而被强行塞进内核的,而不是为了构建一个通用的、优秀的 I/O 模型。
AIO is a horrible ad-hoc design, with the main excuse being “other, less gifted people, made that design, and we are implementing it for compatibility because database people - who seldom have any shred of taste - actually use it”.
对 aio 的抱怨最好的材料是 [2]。客观来说喷的的都对,但并没有什么卵用。客观来说大家都没有选择的时候说啥都不对,早年 InnoDB 因为有 libaio 在 io 处理上确实效果好一些,那凑合着用总比没有好。但现在呢?io_uring 已经被提出来好一会儿了,现在用也不算亏。关于 libaio 的问题网上还有一些比较好的文章,比如 [3],这种材料直接看那篇文章比看我这个刚学的人车轱辘话好很多。不过我们再次为 aio 说句话:如果你的读写快不那么小,负载比较合适的话,使用 aio 并不会比 io_uring 更慢特别多(但它有很多奇怪的行为,这点我们讲 io_uring 的时候会反过来理解这件事情)。
好了,我们回到正题。这次介绍的是文章 io_uring for High-Performance DBMSs: When and How to Use It。在进入这篇文章之前,我们简单定性一下 io_uring 和使用 io_uring 优化的方法:
- (笔者认为)io_uring 某种程度上是 「syscall user-space ring」,是一套异步 + batch 执行 syscall 的框架。这里不仅提供了「异步」的空间,某种程度上也提供了 batch 均摊小 syscall 的空间
- io_uring 要用好需要了解一定的实现和具体的硬件的知识,用户需要知道这些调用能不能真的「异步」起来,如果不能的话需要让它尽量能(比如你丢一个大块 io 或者 fsync 它可能会用内核线程池帮你做)
- io_uring 可能会变成一个比较好的平台,比如 io_uring NVMe passthrou。理论上大家其实都想 bypass kernel,像 DBOS 画了很多饼,但其实不是所有团队都能吃上这个大饼的,没有专人维护要踩这些 bypass 的坑实质相当于实现一边内核已有的这些东西。说了这么多意思是 io_uring 可以作为一个投入产出比比较高的中间选项,很多性能有关的东西会被上收到 io_uring
第三点正如论文 Introduction 一节提到的
Challenges of user-space I/O. User-space I/O frameworks such as DPDK, SPDK, and RDMA bypass the kernel and can deliver high performance on dedicated hardware [27, 35, 41]. However, operating entirely in user space removes OS abstractions such as file systems and TCP networking, making integration difficult for production databases that rely on them. These stacks also require exclusive control of SSDs or NICs [11, 18, 30], which may conflict with deployments where devices must be shared. Consequently, user-space I/O, despite its advantages, has not seen wide adoption and is used mainly in specialized, tightly controlled environments rather than general-purpose systems
笔者最近比较忙,因此跳过了第四节 network 的部分,等之后忙完回头再看看。
Interface of io_uring
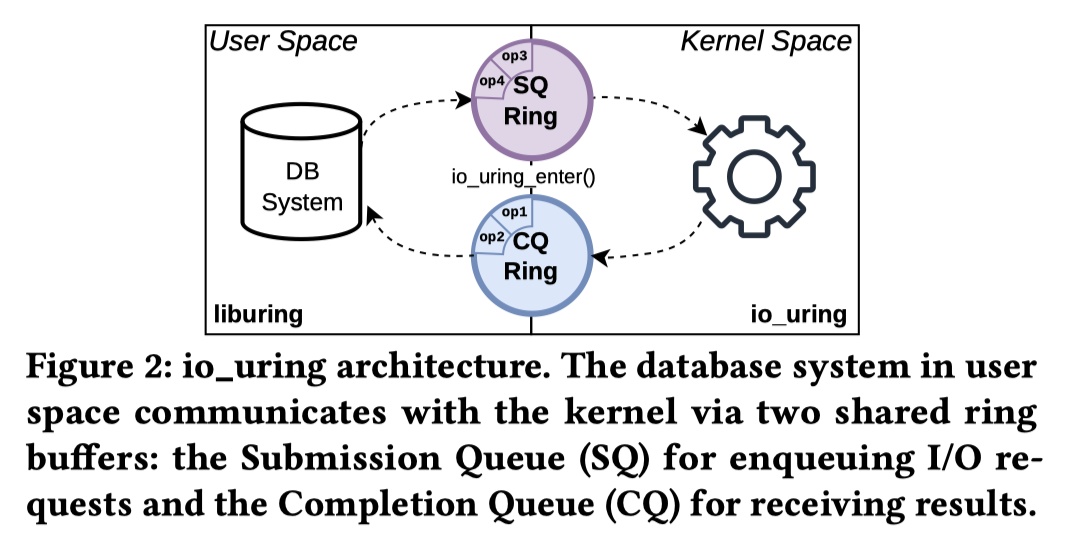
Demands:
- Unification of I/O with io_uring ( Unify epoll and libaio )
- Asynchronous architecture. In contrast to epoll’s readiness-based polling approach, io_uring employs a completion-based model, notifying applications after operations complete rather than when they become possible.
- using two memory-mapped ring buffers with configurable capacity: the Submission Queue (SQ) and the Completion Queue (CQ). These queues are shared between user space and the kernel, avoiding additional data copies when submitting and completing requests.
- Because completions may arrive out of order, each request carries a user-defined identifier to match submissions and completions. io_uring further supports request linking to enforce operation ordering for multiple elements in the SQ.
- Batch processing
- While epoll can report multiple readiness events, each I/O operation, such as read(), still requires its own syscall.
- io_uring allow batch commit to SQ / completion in CQ, amortizes syscall overhead and reduces context switches, allowing the kernel to process operations in bulk.
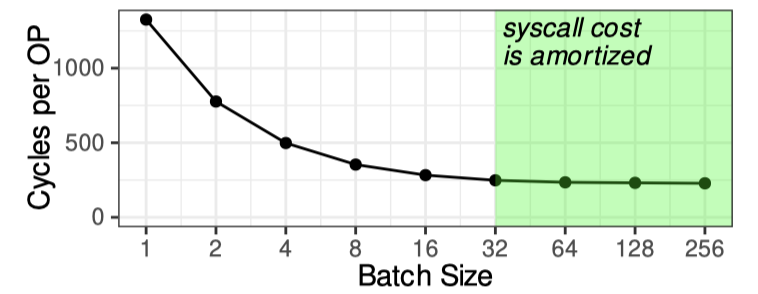
关于第三点它特意附图
Inner Workings of io_uring
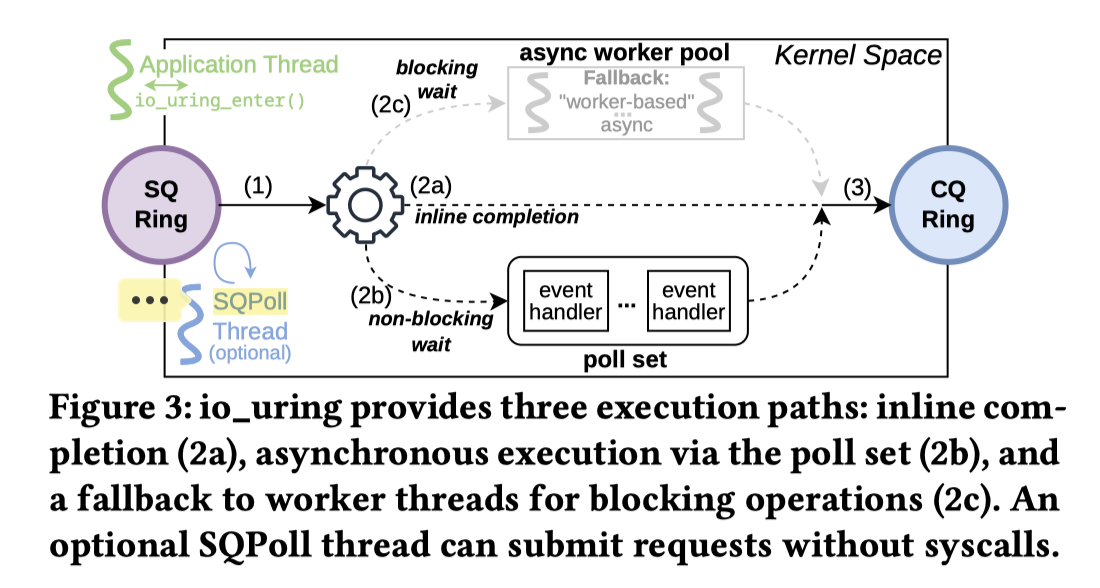
这一节的内容是看图写话,什么意思呢,看这张图然后把这个图解释一遍。我现在来表演一个抄教科书。我们会先把涉及的 API 列一下:
1 | // https://unixism.net/loti/ref-iouring/io_uring_setup.html |
(首先用 io_uring_setup() 来 setup io_uring)
- Issue io
- 默认模式可以在应用的线程中,调用
io_uring_enter()这个 syscall 把操作提交到系统 SQ。enter可以选择to_submit( 队列中提交元素的个数 ),min_complete( 等待请求完成的个数 ),这里可能会 blocking 去等待 min_complete 完成.- 设计者认为,相比于将提交 IO 和等待 IO 分开成两次操作,合并成一次操作有着更高的同步效率。liburing 封装了
io_uring_submit_and_wait(),以便将提交和等待操作合成到单个系统调用中。
- 设计者认为,相比于将提交 IO 和等待 IO 分开成两次操作,合并成一次操作有着更高的同步效率。liburing 封装了
- 如果
io_uring_setup设置了IORING_SETUP_SQPOLL,无需任何 syscall 即可提交任务。内核线程在一段sq_thread_idle时间无操作后会休眠,可以添加元素的时候检测,通过io_uring_enter唤醒。
- 默认模式可以在应用的线程中,调用
- Execution paths in io_uring: 对应图中的 (2) 环节
- Inline execution: first attempts to complete requests inline
- Non-blocking execution: 如果一个操作无法内联(inline)完成,其后续处理方式取决于操作的类型。对于可轮询(pollable)的操作(例如非阻塞套接字读取),io_uring 会注册一个内部事件处理程序(
io_async_wake()),该处理程序会在套接字变为可读状态时被执行(见图 3 中的 2b 步骤)。默认情况下,io_uring 会无限期地等待该操作完成,除非通过OP_LINK_TIMEOUT设置了超时时间。 - Blocking execution:
- 阻塞式的文件系统调用(如
fsync)或大块数据的存储读取。在这种情况下,io_uring 会将执行委托给工作线程(io_worker/io-wq)。这种回退机制(Fallback)比原生的异步路径速度更慢,且开销更高。应用程序可以使用IOSQE_ASYNC标志显式地请求这种行为,强制操作在工作线程中执行。 - 频繁的回退行为或存在大量活跃的
io_worker线程,通常意味着 I/O 模式非最优(suboptimal),可能需要对应用层进行重新设计
- 阻塞式的文件系统调用(如
- Avoiding preemptions for completion-handling,在异步任务完成时,内核通过 (3) 的 task work (一种内核延迟任务机制)来江完成的任务加入到 CQ,这个有一些可能的执行时机
- 默认情况下,只要应用程序从用户态切换到内核态,这个
task_work就会运行。如果线程正处于忙碌状态(例如正在执行数据库的 join 或 scan 操作),内核可能会发出核间中断(IPI)来强制处理待处理的完成项。这实质上抢占了应用程序的运行,破坏了 CPU 缓存的局部性(cache locality),增加了延迟抖动(jitter),并降低了批处理效率。 - 为了缓解这些影响,io_uring 提供了
COOP_TASKRUN标志(简称 CoopTR),它可以减少 IPI 的发生并允许应用程序延迟task_work的执行(通常是下一次系统调用时执行)。然而,在这种模式下,完成项的处理仍然会在任何内核态-用户态切换时发生,甚至包括那些不相关的系统调用(如malloc()底层触发的系统调用)。由于这种抢占会带来副作用,默认模式和协作模式(CoopTR)都不太适合现代高性能数据库管理系统(DBMS)。 - 相比之下,
DEFER_TASKRUN标志(简称 DeferTR)仅在调用io_uring_enter时才会运行task_work。这是推荐的模式,因为它给予了应用程序更多的控制权,并消除了不必要的抢占。因此,除非另有说明,我们在本文的剩余部分都使用该模式。
- 默认情况下,只要应用程序从用户态切换到内核态,这个
这里还有一些 io_uring register buffer 和 register fd 的接口,具体功能如下:
注册缓冲区是一项优化措施,与
O_DIRECT(直接 IO)读写配合使用时非常有用。 它的原理是:在缓冲区注册时,将其指定的内存范围映射到内核一次,而不是在每次对该区域执行 IO 操作时都重复进行映射和解映射(map and unmap)。此外,它还避免了在每次 IO 时都要去操作(频繁增减)内存页的引用计数(page reference counts)。相比普通文件,使用注册文件进行操作时的单次开销更低。这是因为(对于普通文件),内核必须在每次操作开始时获取文件的引用计数,并在操作结束时释放它。
当进程的文件表被共享时——例如,如果该进程曾经创建过任何线程——这种(引用计数管理的)开销甚至会变得更大。
使用注册文件可以显著减少在对文件执行操作的请求中,涉及文件引用管理所带来的开销。
Efficient Storage I/O with io_uring
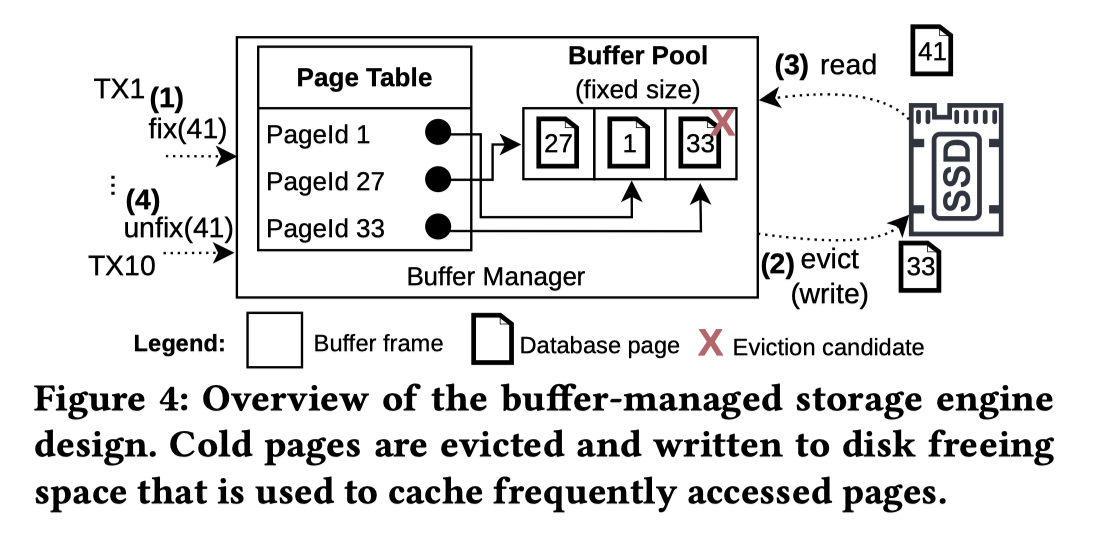
这里在 Storage 层的例子如上,给的硬件环境是 「3.7 GHz AMD server (Kernel 6.15) with an array of eight modern PCIe 5.0 NVMe SSDs (Kioxia CM7-R)」,测 ycsb 等环境的负载,接口和负载是:
- 对于 YCSB: 我们加载了 1000 万个 Tuple(8 Bytes Key,128 Bytes Value)。算上索引结构和元数据,在使用 4 KiB 页面进行均匀随机更新的情况下,会导致大约 70% 的缺页概率(page fault probability),从而产生一个非常适合存储分析的 I/O 密集型负载。
- 对于 TPC-C: 我们分别使用 1 个和 100 个 warehouses,以研究“绝大部分在内存中(mostly in-memory)”与“绝大部分在内存外(mostly out-of-memory)”这两种设置下的影响。
fix(page_id)加载 Page,尝试 evictunfix(page_id, is_dirty): 表示不需要 Page这里基准硬件如下:

这里分了好几条来处理,具体见下图:
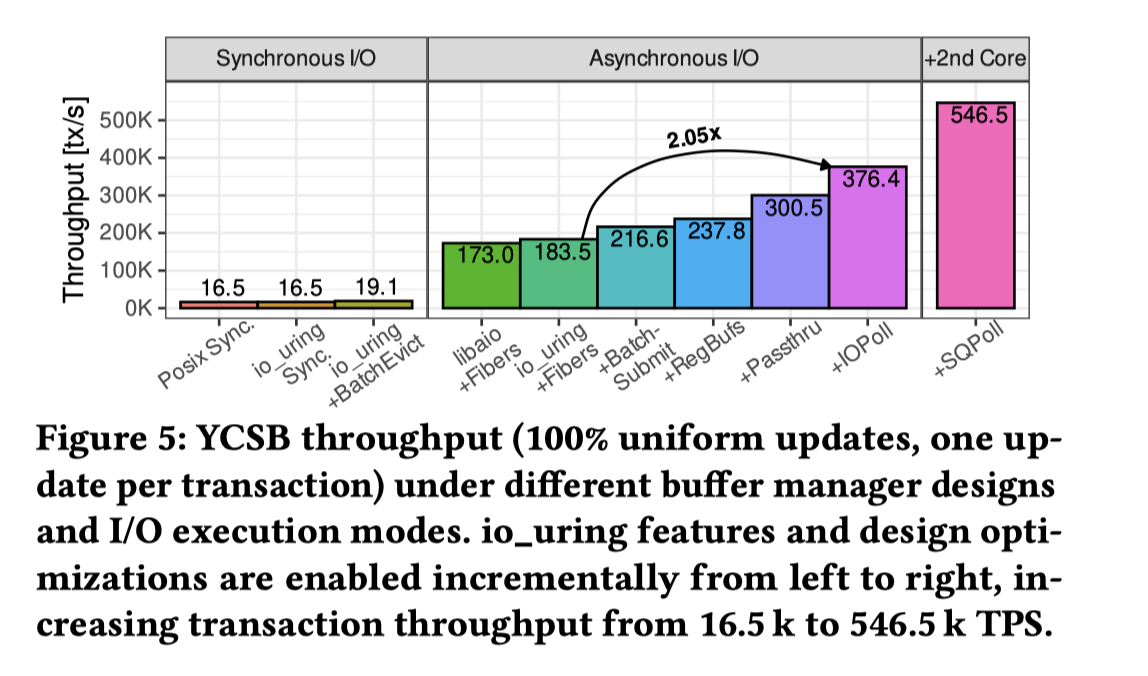
- 用 io_uring 和
io_uring_enter代替preadpwrite,一切走同步: 跟 pread pwrite 差不多 - 走 io_uring + BatchEvict,
io_uring_enter提交一组 io,有部分提升 - 使用 io_uring 默认配置 + Boost.Fiber,这里提升本质上是交错计算和 io,切 fiber 寄存器大概十多 cycles,新的瓶颈上升到了 CPU。
- 为了降低 CPU 这里允许 Batch-Submit Read 和 Adaptive Read。Adaptive 在于 BatchRead 会增加延迟,这里回看排队的任务数,如果任务队列不多就单独请求(延迟有限),否则 Batch 来降低 syscall 开销
- RegBufs: 这里没看懂为什么能提升这么多。摘录一下原文:Registered buffers reduce copies. io_uring allows user-space buffers to be registered once during initialization, avoiding perrequest page pinning and kernel-user copies. The kernel then performs DMA directly into user memory, eliminating these overheads. For our YCSB workload, this zero-copy optimization improves throughput by about 11%, reaching 238 k tx/s (Figure 5, +RegBufs). 我理解这里不一定能减少 copy?
- NVMe passthrough: 看论文 [7],用
IO_URING_CMD直接发 NVMe 命令 - IOPoll: 轮询块设备来提交,后面有性能分析。
- SQPoll: 配置专门的 kernel 线程,来 pool SQ,这个就避免了
io_uring_enter()一层 syscall,
接下来这里测了 TPC-C,这样更 copute bound 的场景,可以看到这里面跟负载有关,如果缓存命中率高或者瓶颈不在读盘上,这里 io_uring 效果就不一定好了,
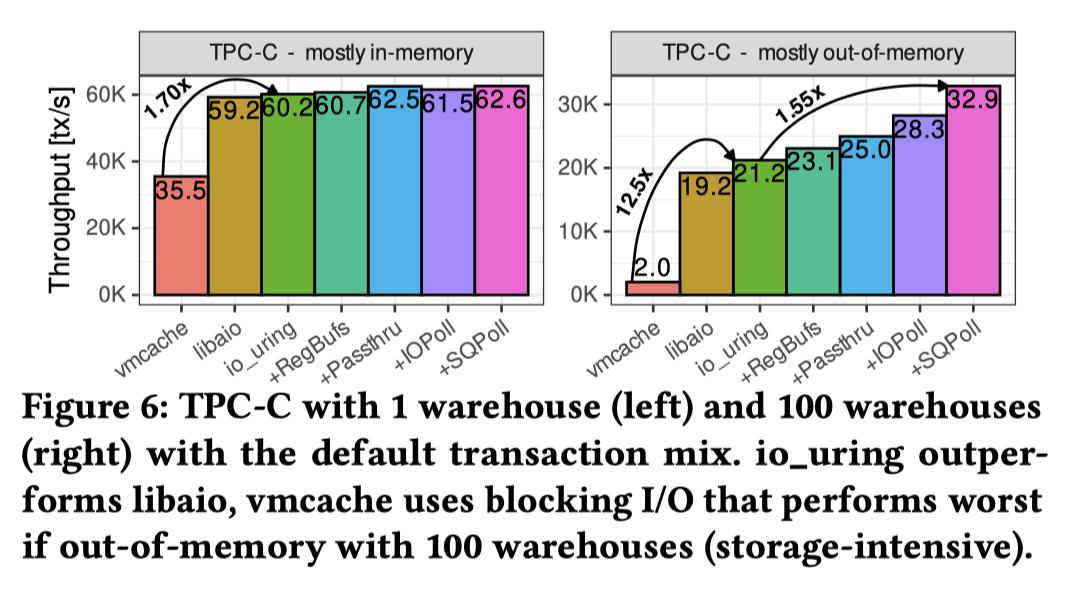
一些性能相关的细节
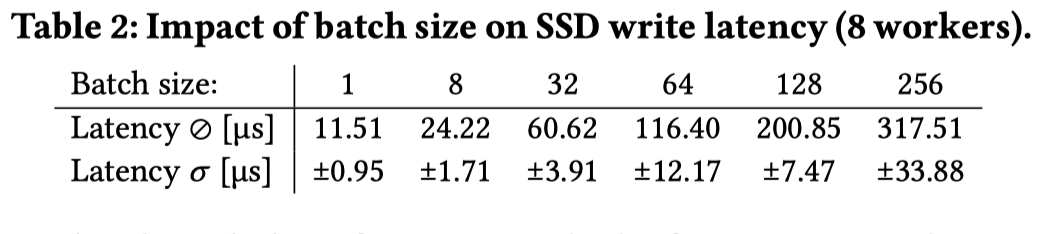
第一个是 Batching 本质上一是减少 syscall,但是 batching 也会一起调度请求,一起调度有两方面,一个是 io 的队列深度,一个是完成任务的 Latency。但感觉这个既有 io 队列深度的影响又有调度的影响,感觉这里收的不是很清楚。这里固定 1.5 MIOPS 的吞吐来访问,保证低于 SSD 提供的吞吐。如果这里 iops 过高,也可能打满这个 io 队列。
然后这里测试了多线程(之前是一个线程来测试),这里采用 one-ring-per-thread 的方式。
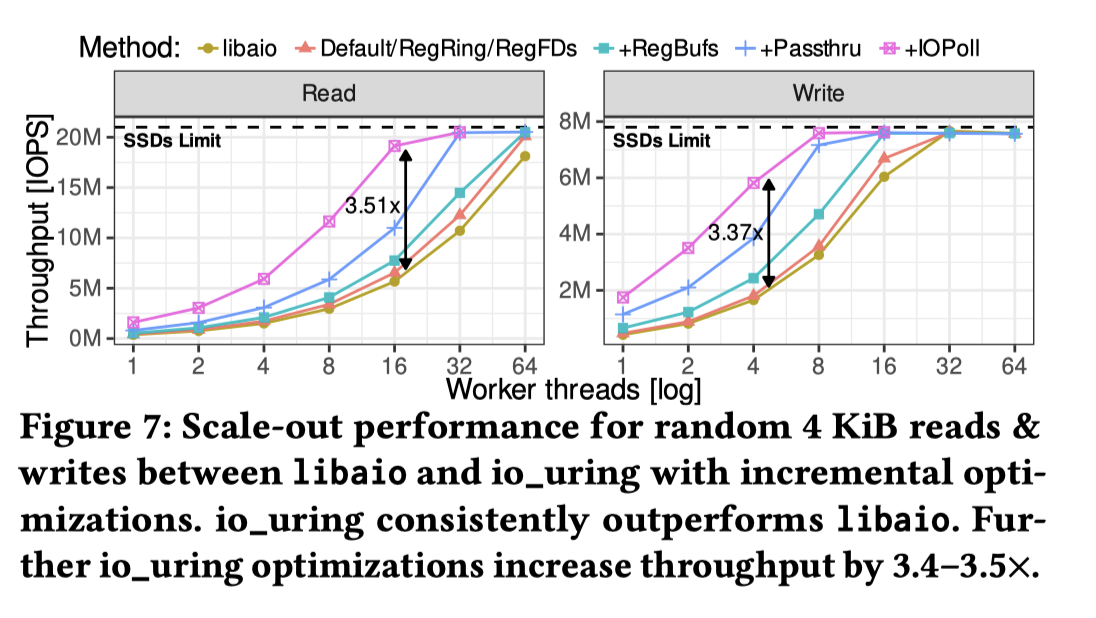
The benefit of io_uring optimizations increases with scale: registered buffers (+RegBufs) reduce CPU overhead, while NVMe passthrough (+Passthru) and IOPoll in particular deliver substantial throughput improvements of 3.4–3.5× saturating the SSD array with 18 and 6 cores, respectively.
额,就是说 Passthru 绕过存储栈呗…
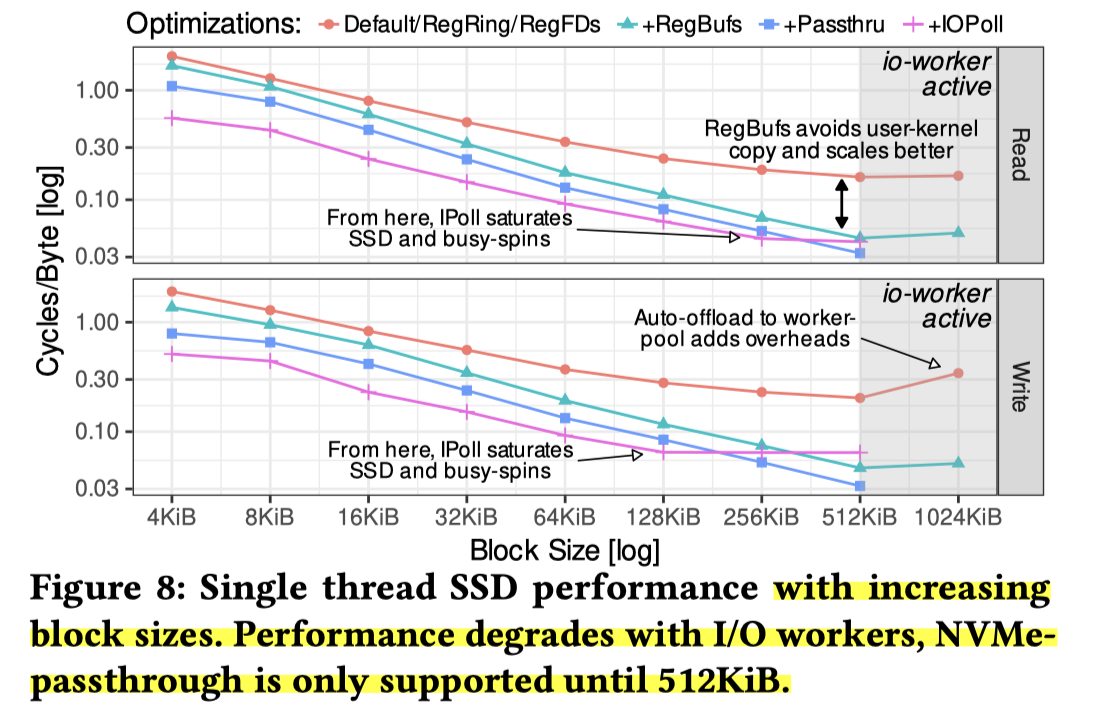
剩下还测了 Block size,大概内容就像下面,但是有一些次级结论:
大块 I/O 可能会适得其反。 正如第 2.2 节所讨论的,一旦超过某些阈值,就会触发异步工作线程(asynchronous worker threads),这标志着系统回退到了较慢的 I/O 路径。
- 首先,如果块大小超过
max_hw_sectors_kb(如果启用了 IOMMU,该值可能仅为 128 KiB),即使在低 I/O 深度下也会生成工作线程,因为单个请求就超过了最大 DMA 大小。- 其次,在使用
O_DIRECT时,一旦批量请求的数量超过nr_requests(裸机为 1023,我们的云虚拟机为 127),工作线程就会出现;在某些消费级 SSD 上,即使不使用O_DIRECT也会出现这种情况。- 第三,当块大小超过 512 KiB(即
max_segments上限)时,内部又会再次使用异步工作线程来处理 I/O。虽然大块 I/O 能提高效率并充分利用 PCIe 5 的带宽,但超越这些软件或硬件限制会导致工作线程回退(worker fallback),从而在
io_uring中重新引入延迟和 CPU 开销。
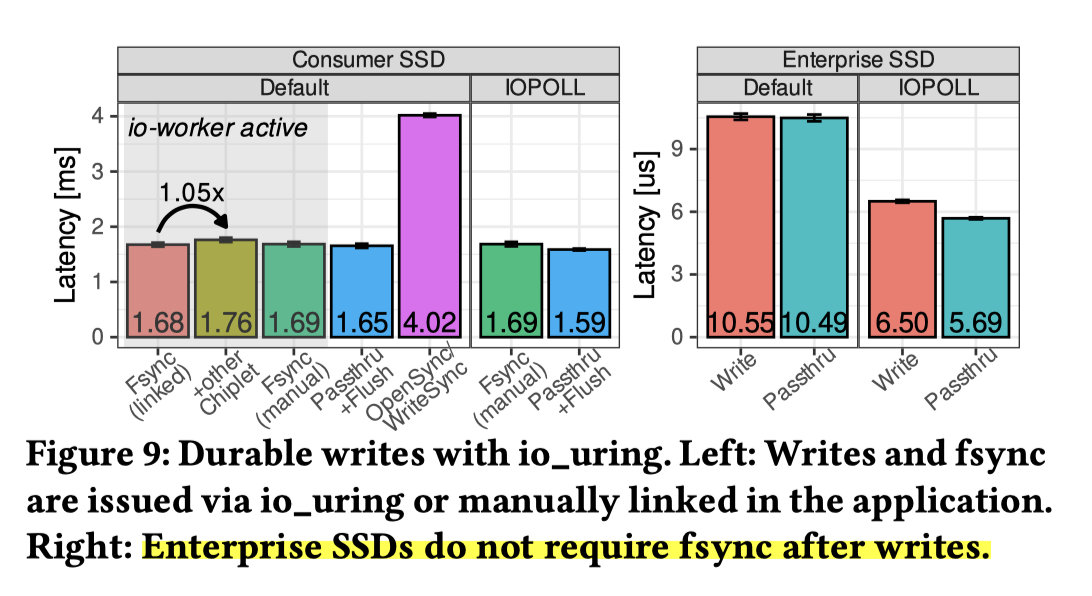
最后一块是 Durable 的场景,图如下。核心问题是 fsync io_uring 中是 Blocking 的,一个是需要赛道 io-worker 里头,另一个是无法 IOPOLL,这里幸好企业级 SSD(带掉电保护 PLP 和 Buffer)延迟极低,甚至无需显式 fsync;消费级 SSD 受限于物理 fsync 毫秒级的高延迟,如果要做的话可能需要 NVMe passthru 等方式来加速这块的效果。
Guildlines
Guildlines 第一条很简单,需要负载合适才能拿到足够收益。你都 cache 了缓存命中率 99% io 又不慢那可能这事情就不急。
第二条也很简单,io_uring 作为异步操作,还是需要应用上层配合的,不然你真的可以把 io_uring 绕一大圈还比正常服务慢,比如我 enter 是 syscall 然后又用 enter 去 reap CQ,这样肯定是可以的,但是比较费,这里和 coroutine 呀什么的结合起来,然后再把请求按照论文说的方式调度起来才能有比较好的效果。对于network一些部分,最好用 ring-per-thread 的方式来组织。
这里也推荐了 DeferTR(DEFER_TASKRUN)+ 单提交者模式,并认为在特定场景(如高IOPS或低延迟目标)下,SQPoll模式能提升性能,但需要牺牲一个专用轮询核心。应尽量避免操作退化为io_worker线程执行(如大块I/O或fsync,甚至后面讲 PG 的例子提到,直接调用fsync()而非通过io_uring,避免产生io_worker),这个就跟你线程执行性能上五五开了。并教育我们你都想到 io_uring 代码了,还是要懂点硬件知识。
最后就是有效利用 io_uring 上面提到的各种特性。
Reference
- https://lwn.net/Articles/671657/
- https://lwn.net/Articles/724198/
- https://steinslab.io/archives/2865#fn:LWN_aio
- https://www.usenix.org/system/files/fast24-joshi.pdf
- https://unixism.net/loti/ref-iouring/io_uring_setup.html
- https://unixism.net/loti/ref-iouring/io_uring_enter.html
- https://www.usenix.org/system/files/fast24-joshi.pdf